




1. 痛点:被显存“卡脖子”的巨型模型
当前,最前沿的开源大模型几乎都采用了稀疏 MoE(混合专家)架构。近期部分 MoE 模型的参数规模已达到至万亿级别,导致对计算资源的需求急剧增加。然而,部署万亿参数级别的 MoE 模型门槛极高——不仅依赖昂贵的GPU算力集群支持,更伴随着巨大的能耗成本。这些庞然大物对硬件的贪婪需求,对广大开发者和中小企业筑起了一道难以逾越的“显存高墙”。只有少数大型企业有能力不计成本地在高性能 GPU 集群上部署这些模型。市场迫切需要一种更具成本效益的替代方案。
2. 破局:秘密
如何在显存受限的GPU上容纳万亿参数?核心策略是:CPU+GPU混合计算,扬长避短。
MoE 模型结构的核心特性:
MoE 专家(FFN): 在稀疏 MoE 模型中,专家(FFN)参数占据了绝对主导地位,通常约占模型总参数的 95%,但在推理过程中,只有极少量的专家会被“选择性激活”。这类运算属于典型的访存密集型(Memory-bound)。
Attention 模块: 参数量极少,但计算非常复杂且频繁。这类运算属于典型的计算密集型(Compute-bound)。
正是利用这一核心特性,将大语言模型推理中的不同计算强度任务策略性地分配给最合适的硬件——即让 CPU 和 GPU 分别处理它们最擅长的计算模式,克服依赖单一硬件类型的局限性。这种方法允许使用更经济实惠的硬件配置,从而降低了总拥有成本(TCO),最终实现了在可控成本下的高效推理。
GPU(昂贵的算力与稀缺的显存): 负责处理那些“计算密集、参数量小”的核心任务(如Attention、Shared Experts)。无论显存多紧张,这些必须留在 GPU 里,以保证计算速度。
CPU + 内存(成本低): 负责那 90% 以上的“冷门”专家参数(Routed Experts)。虽然CPU算力弱,但在处理这些主要受限于带宽的“搬运”任务时,配合大容量内存,它表现得游刃有余。
这种架构将 CPU的大容量内存与GPU的高算力结合,打破了单一硬件的局限。让单台服务器化身为一个高效的异构计算节点,在不牺牲太多性能的前提下,将硬件成本压缩了数倍甚至十数倍。
- 实验:性价比之选
为了验证这一方案,我们在单台配备NVIDIA RTX 5090 (32GB) 和大容量内存的服务器上部署了Kimi-K2-Thinking模型(1TB参数),并进行了严苛的测试。
实验结果令人振奋:
在验证实验中,Kimi-K2-Thinking模型的推理服务分别部署在单张和双张RTX 5090 GPU上,并配备了约1TB内存,其生成速度达到了交互可用的水平(具备15-20 tokens/s的处理能力)。模型信息与实验数据如下表:
模型推理服务测试如下图:

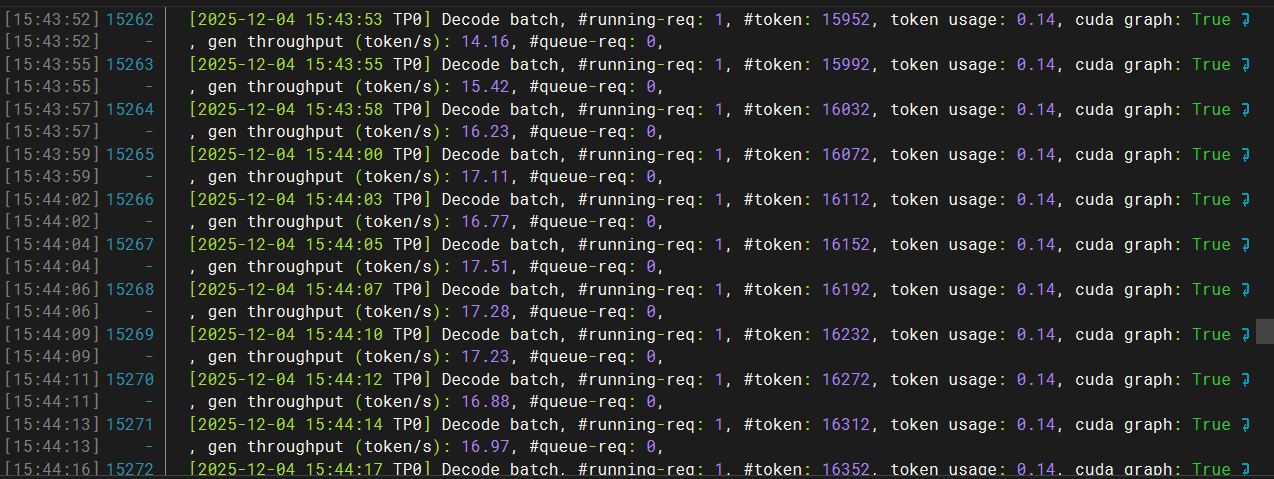
使用两张RTX 5090 GPU可实现约20 tokens/s的生成速度。推理日志如下图:

使用单张RTX 5090 GPU可实现约16 tokens/s的生成速度。推理日志如下图:
- 价值:为AI普及铺平道路
这项技术不仅仅是一次性能优化,它更是一场AI算力的“平权运动”。其应用潜力广泛,对MoE模型性能有高期待,但受限于有限GPU资源的开发者或企业,提供了一种可行的解决方案。
极致的成本效益: 用户不再需要租用昂贵的云端集群。一台配置了大内存和单张高端 GPU 的工作站,即可成为私有化的 AI 推理中心。
隐私与安全: 使得在本地离线运行顶级模型成为可能,数据无需上传云端,解决敏感数据的安全顾虑。
降低门槛: 学生、独立开发者和初创公司现在也有机会接触和研究最前沿的 SOTA模型。
- 结语:迈向未来的优化之路
降低万亿参数大模型服务的资源门槛,是向更高效、低成本的大规模模型部署迈进的关键一步。不计成本堆砌硬件也并不是通往 AGI 的唯一路径,精细化的软硬件协同优化才是未来。
这一突破为未来人工智能的普及和优化铺平了道路。也许在不久的将来,每个人的桌面上都将运行着一个拥有万亿智慧的“超级大脑”。
