当前已正在运行
5,325 +个分布式算力设备

盛见AITHER安泰算力云
Fedimoss AITHER
Computing Cloud
AI 浪潮席卷全球,AI 分布式算力云成发展核心 。
却面临算力不均、成本高昂等困境,盛见 AITHER 安泰算力云可有效破解难题 。
往下滑动查看更多
核心功能概览
核心功能
-

组件GPU集群整合资源
平台可以聚合集群内(含混合云)的所有 GPU 资源。它旨在支持所有的 GPU 厂商,包括英伟达,苹果,AMD,英特尔...
-

模型部署
为在不同GPU上运行不同大模型选择最佳的推理引擎。支持的首个推理引擎是 LLaMA.cpp,允许部署来自 Hugging Face ...
-

推理引擎
在资源充足的情况下,默认将模型全部卸载到GPU,以实现最佳性能的推理加速。若GPU 资源相对不足,系统会同时使...
-

快速与现有应用集成
提供了与 OpenAI 兼容的 API,并提供了大模型试验场。试验场可以让 AI 开发人员能够调试大模型,并将其快速集成到自...
-

GPU 和 LLM 的观测指标
提供全面的性能、利用率和状态监控指标。管理员可以实时监控资源利用率和系统状态。基于这些指标:管理员可以进行...
-

认证和访问控制
为企业提供身份验证和 RBAC(Role-based Access Control)功能。平台上的用户可以拥有管理员或普通用户角色...
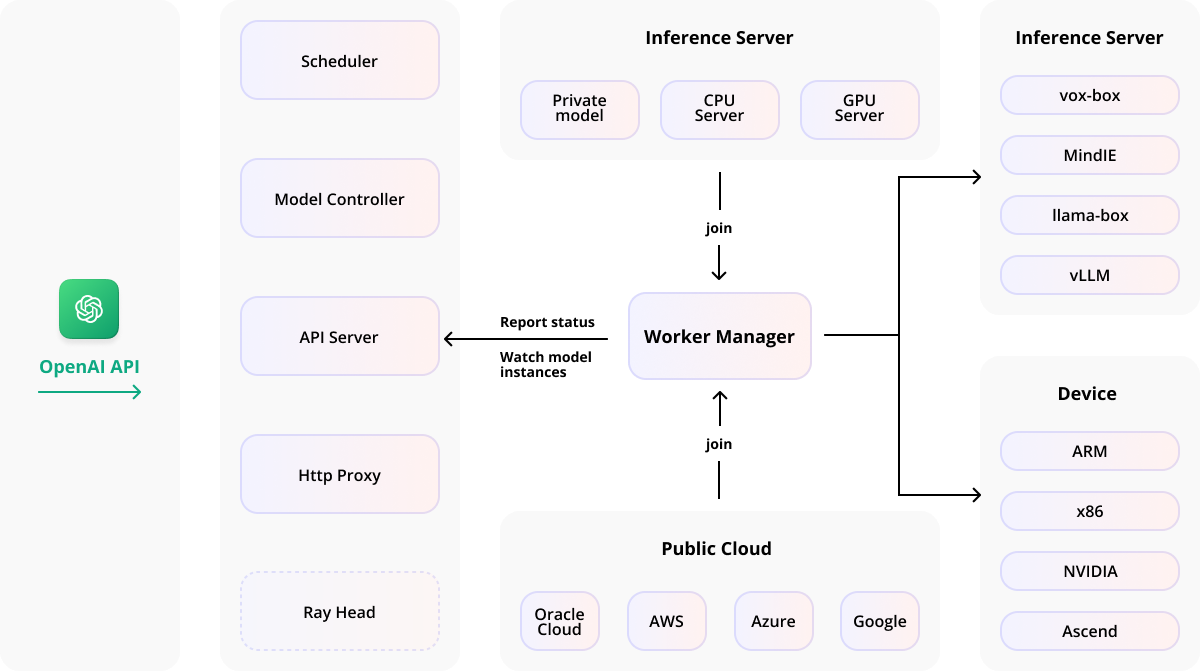
平台架构蓝图
平台架构设计
平台架构设计,含模块、服务器及关联流程
系统关键特性
关键功能指标
支持多设备 GPU、多模型,集成推理后端,具备分布式推理等能力,轻量且兼容 OpenAI API
-
GPU兼容性
无缝支持 Apple Mac、Windows PC 和 Linux...
-
模型支持
支持大语言模型(LLM)、多模态模型(VLM)...
-
后端推理
集成 llama-box(llama.cpp 和 stable-diffusion...
-
多版本支持
可同时运行多个版本的推理后端,满足不同模型...
-
分布式推理能力
支持单节点和多节点多 GPU 推理,包括...
-
可拓展GPU架构
通过向基础设施中添加更多 GPU 或节点...
-
模型稳定性
通过自动故障恢复、多实例冗余和推理请求负...
-
智能部署评估
自动评估模型资源需求、后端与架构兼容...
-
自动化调度
根据可用资源动态分配模型...
-
轻量级Python包
依赖项少,运维开销低
-
兼容OpenAI API
完全兼容 OpenAI 的 API 规范,便于无缝...
-
用户和密钥管理
简化用户和 API 密钥的管理流程...
广泛、灵活、丰富
方案优势
广泛的兼容性、丰富的模型支持、灵活的扩展性、多样的推理后端,为 AI 应用提供高效、便捷且安全的解决方案。
-

广泛的兼容性
适配多品牌 GPU、多设备、多架构及主流系统,兼容深度学习框架与 HPC 软件,支持容器化集成。
-

丰富的模型适配
覆盖 LLMs 等多种 AI 模型及多模态模型,可从多个主流模型仓库部署,满足多样需求。
-

强大的可扩展性与分布式推理
支持单 / 多节点、单 / 多卡推理,自动分布式运行大模型,新版本特性进一步提升推理效率。
-

多样化推理后端
支持 vLLM(生产级优化)、llama.cpp(多平台兼容)等推理后端,自动匹配模型类型,兼顾性能...
-

轻量级与便捷性
轻量级 Python 包,安装简便,兼具自动与手动调度,兼容 OpenAI 标准 API,上手快。
-

全面的管理与监控功能
含用户密钥管理、实时多维度监控,支持多模型对比,具备安全访问控制,保障企业使用。
场景覆盖概览
应用场景
系统应用场景丰富,支持跨平台,整合 Mac、Windows PC 等 GPU 资源,降低开发团队成本
-
跨平台
整合现有的 Mac、Windows PC 和其他 GPU 资源,为开发团队提供低成本的 LLMaaS。
-

算力资源有限
在资源有限的环境下,聚合多个边缘节点,提供基于 CPU 资源的 LLMaaS。
-

私有化部署
在数据中心构建企业自身的企业级 LLMaaS,用于无法在云中托管的高度敏感的工作负载。